Recently, a paper titled "Learning and Processing the ordinal information of temporal sequences in recurrent neural circuits" by Mi Yuanyuan's research group from the Department of Psychology at Tsinghua University has been accepted at NeurIPS 2023. The co-first authors of this study are Dr. Zou Xiaolong and Chu Zhikun (a doctoral student at Chongqing University Medical School), with Associate Professor Mi Yuanyuan as the corresponding author.
Background
Processing temporal sequences is one of the core cognitive functions of the brain. Temporal sequences consist of a series of events (content) that unfold in time according to a specific "temporal order" structure, such as in actions, gait, or speech. For example, in language processing, the sentence "We want to listen to music" contains three different items (subject, predicate, and object) that unfold sequentially over time. Furthermore, the pronunciation of any word in the sentence, such as "listen," is also a temporal sequence composed of basic phonemes; only when these fundamental phonemes appear in the correct temporal order can we effectively recognize them. Compared to purely spatial information processing, the technical challenge of temporal sequence processing lies in effectively extracting feature information from input signals at different moments and integrating them according to their temporal order to make correct judgments. To date, artificial intelligence algorithms still lag far behind humans in recognizing temporal sequences.
The brain constantly processes such temporal sequences in tasks like speech recognition and action judgment. Substantial experimental research shows that "temporal structure" and "content" are dissociated in brain representations (Xie et al., Science, 2022). For instance, neurophysiological experiments in non-human primates found that a large proportion of neurons in the dorsolateral prefrontal cortex and parietal cortex are highly sensitive to the "temporal structure" of visual stimuli on screen, but not sensitive to other physical attributes such as color or orientation (i.e., content). Similar representations of temporal structure have been observed in auditory and language sequence processing. However, the neural computational mechanisms behind this "dissociated representation of temporal structure and content" remain unclear. Additionally, the order structures hidden behind multiple related sequences display tree-like structures (Figure 1). For example, the temporal structures of four keywords "water, wash, your, year" form a two-layer tree structure. Specifically, starting from the root, the words "water" and "wash" form one branch at the first layer because they share the same first syllable, while the words "your" and "year" form another branch. At the second layer, "wash" and "water" diverge again to form new branches, as do "your" and "year." Existing experimental research suggests that such tree-like temporal structures can be stored in a low-dimensional neural activity space in the prefrontal cortex (Zhou et al., Nature, 2021). But how do our brain's local neural circuits learn such abstract tree-like temporal structures?
More importantly, the brain can extract "tree-like structures" as templates (generally called event schemas) from multiple existing temporal sequence samples and flexibly and stably combine these templates with different "content" to form new temporal sequences, thereby effectively promoting transfer learning capabilities.
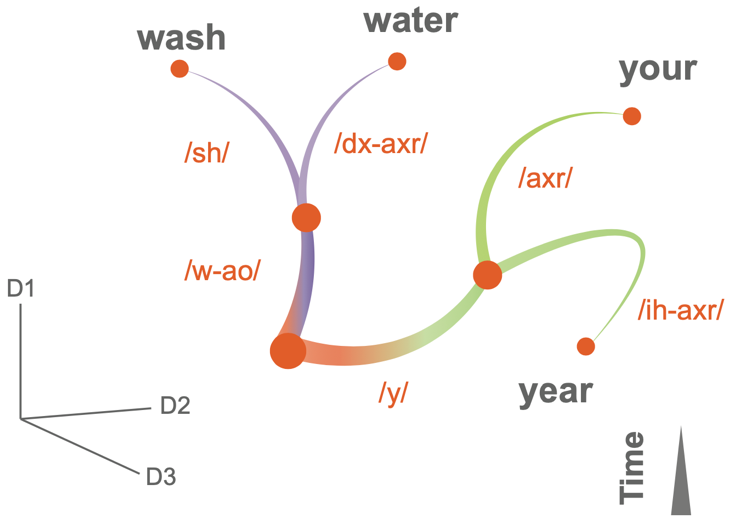
Figure 1: Tree-like temporal structure formed by four keywords "water, wash, your, year".
Proposing a Learning Paradigm that Can Acquire "Tree-like Temporal Structures"
To study how our brain's local neural circuits learn the tree-like temporal structures behind temporal sequences, and to explore the computational advantages of such temporal structures, we employed a recurrent neural network model (Figure 2A) and proposed a new learning paradigm for recurrent neural networks (Figure 2B).
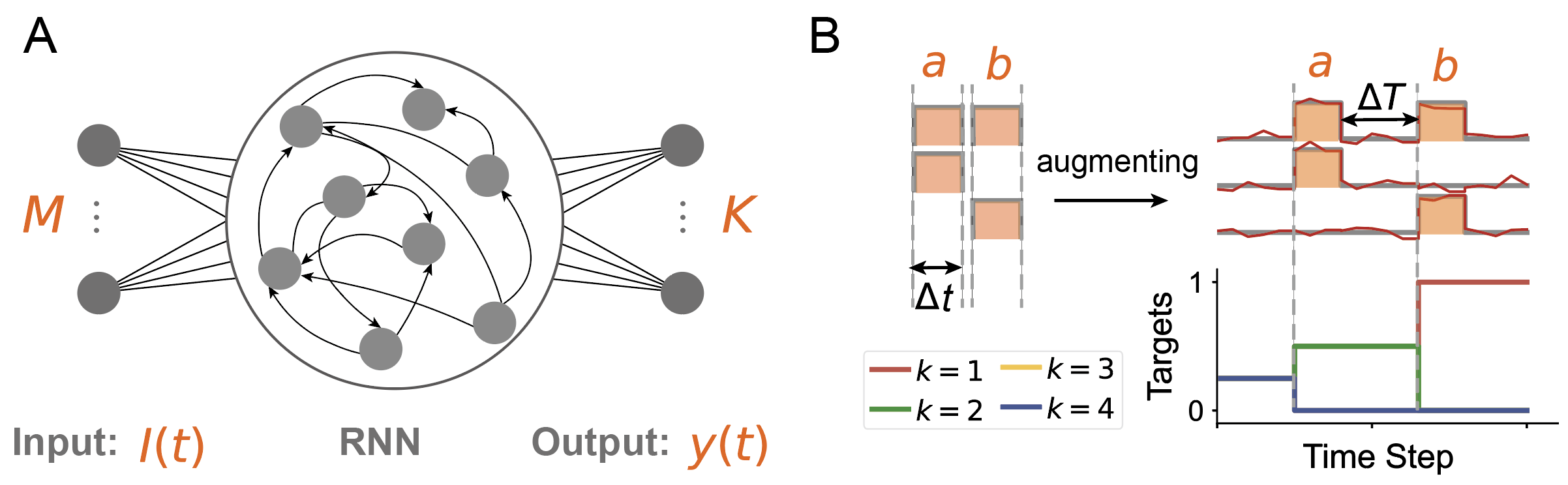
Figure 2: (A) The recurrent neural network model includes three parts: 1) an input layer that transmits temporal sequence information; 2) a recurrent network layer that can store abstract temporal structure templates from multiple temporal sequences; 3) an output layer that expresses the network's classification results for input information. (B) Learning paradigm. Our proposed new learning paradigm mainly considers two important factors: preprocessing strategies for input information sequences based on content similarities and differences (upper right in B) and hierarchical objective functions for the "coarse-to-fine" recognition process (lower right in B).
We first explored the effectiveness of the learning paradigm using artificially synthesized data with the same tree-like structure as in Figure 1 (Figure 3A). Specifically: First, we constructed three different items (a, b, c), with any item having three input channels (left in Figure 2B). Next, we randomly selected two of these items to form a sequence, resulting in four sequences: a-b, a-c, b-a, b-c. These four sequences implicitly contain a tree-like temporal structure identical to that in Figure 1 (Figure 3A). Following the learning paradigm in Figure 2B, we trained the network using a supervised learning algorithm. We found that: 1) The trained recurrent neural network formed multiple stable attractor states (marked 'x' in the middle left of Figure 3B) in its activity space to represent different "content" in temporal sequences; 2) The channels between any two adjacent "contents" in any sequence were also stable (right of Figure 3B); 3) The evolutionary trajectories of the four sequences in the network activity state space exhibited a tree-like structure (trajectories in different colors in Figure 3B). Therefore, our proposed learning paradigm enables local neural circuits to learn neural representations of "tree-like temporal structures" that align with experimental results.
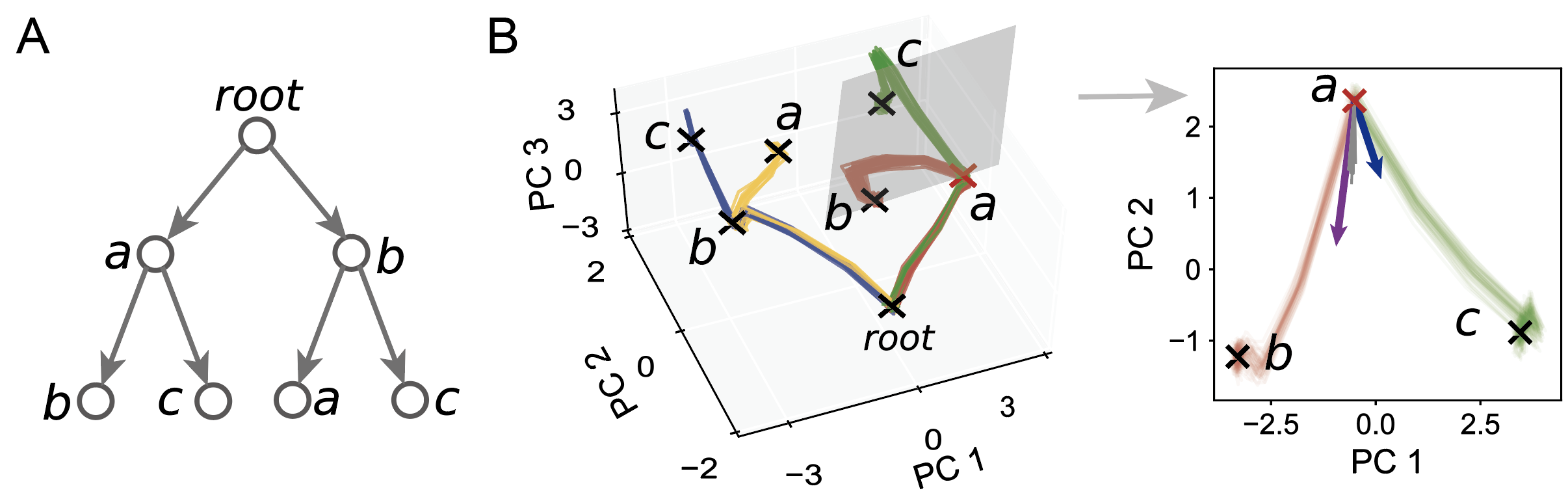
Figure 3: (A) The implicit tree-like temporal structure behind artificially synthesized data. (B) (Left) The tree-like attractor structure learned by the recurrent network layer, (Right) The channels between any two attractors representing different content are also stable. For example, in the sequences a-b and a-c, the first two feature directions from the attractor representing content a in the network activity space point toward the two attractors representing contents b and c, respectively, and their eigenvalues are less than 1 (an eigenvalue less than 1 indicates that the feature direction is stable).
What computational advantages does the "dissociated representation of tree-like temporal structure and content" in the brain's local neural circuits offer? We explored the computational advantages of this brain information processing mechanism in transfer learning and keyword speech recognition processes.
Neural Representation of "Tree-like Temporal Structures" Effectively Promotes "Transfer Learning"
We used the "tree-like temporal structure" learned in Figure 3 as a template, combined it with new "content" (such as temporal features of different phonemes), and thereby formed a new set of temporal sequences (left of Figure 4A) to further explore the computational advantages of tree-like sequence templates in transfer learning. In this transfer learning task, to effectively reuse the tree-like temporal structure in the network activity space from Figure 3 as a template, we fixed the connection structure between neurons in the recurrent network and only trained the connections between input signals and the recurrent network. We found that: 1) The new set of temporal sequences indeed reused the tree-like temporal structure learned by the recurrent network in Figure 3 (right of Figure 4A); 2) The reuse of tree-like temporal structures effectively accelerated the network's transfer learning capability (Figure 4B).
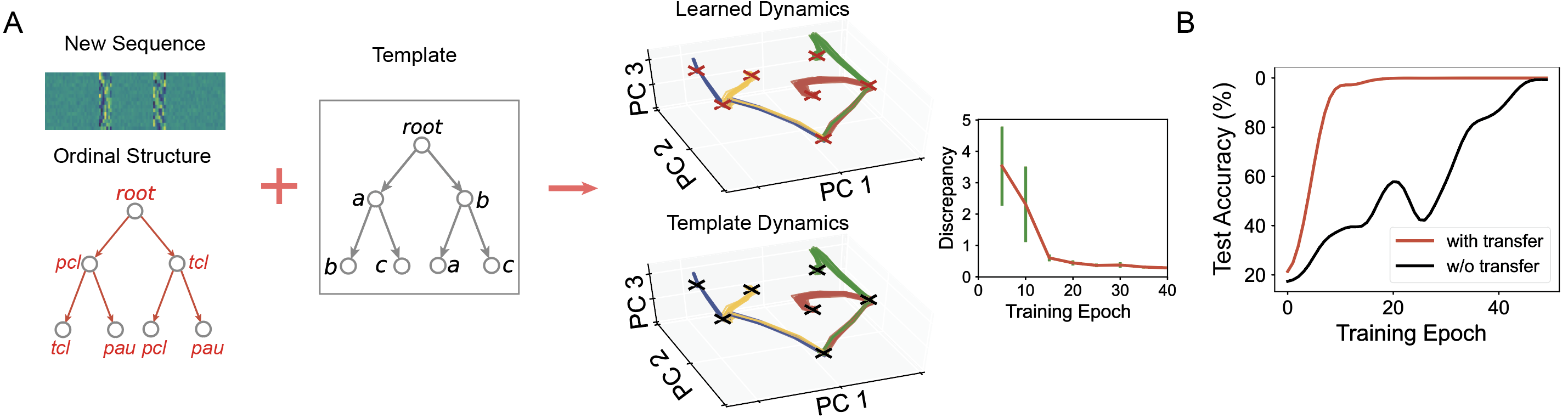
Figure 4: Tree-like attractor temporal structure as a template effectively promotes transfer learning
Neural Representation of "Tree-like Temporal Structures" Effectively Enhances the Robustness of "Keyword" Speech Recognition
The brain can robustly recognize stretched or compressed "keyword" speech information, which is particularly challenging in machine learning. We propose that "dissociated representation of tree-like temporal structure and content" provides an effective solution for this. This is because for any keyword as a temporal sequence, each phoneme ('content') is combined according to a specific sequence. Our research found that neural networks can robustly recognize stretched or compressed keyword speech sequences through the temporal structure behind phoneme content learned during their learning process, significantly outperforming control models, as shown in Figure 5.
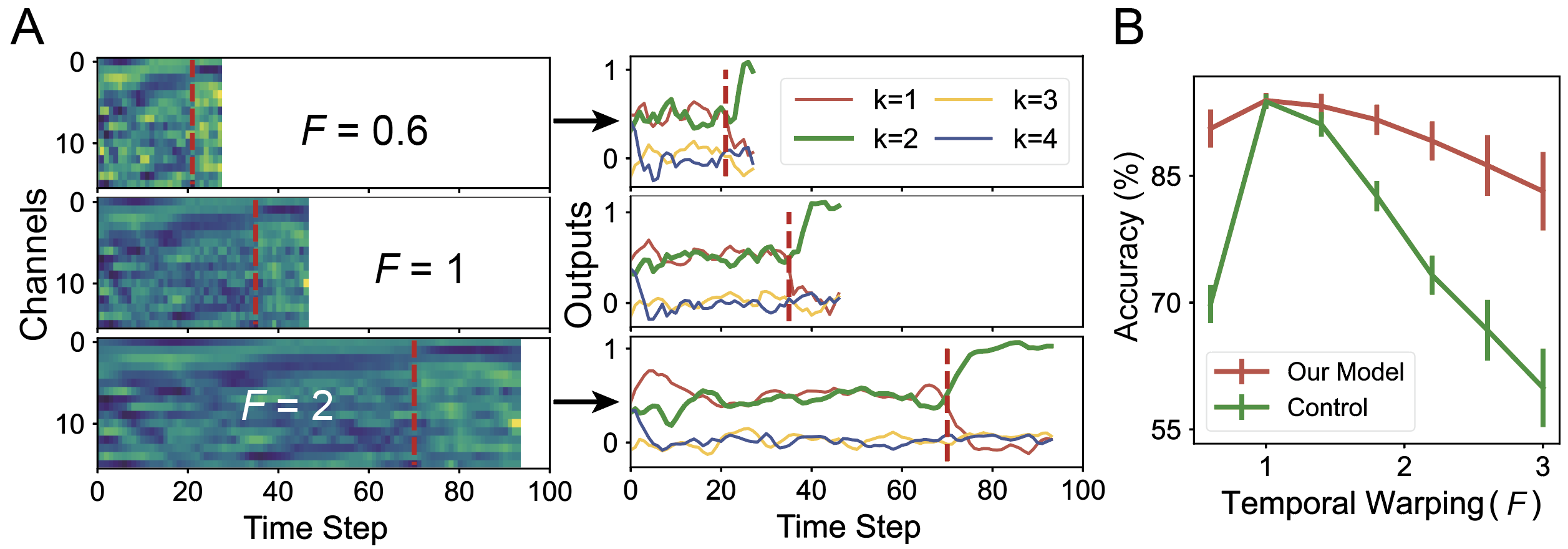
Figure 5: Tree-like attractor structure helps improve the robustness of keyword speech recognition.